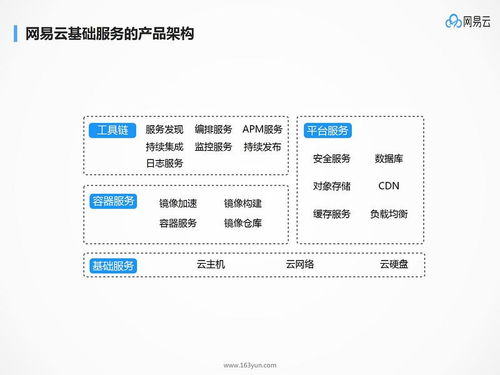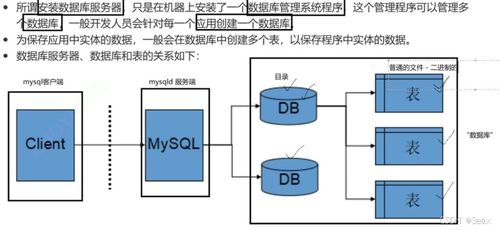
在信息爆炸的今天,企業(yè)每天都需要處理TB甚至PB級(jí)別的海量數(shù)據(jù)。傳統(tǒng)的數(shù)據(jù)處理技術(shù)在面對(duì)如此龐大的數(shù)據(jù)量時(shí),往往在性能、擴(kuò)展性和成本上捉襟見肘。此時(shí),以Hadoop為核心的離線批處理技術(shù)應(yīng)運(yùn)而生,成為了大數(shù)據(jù)領(lǐng)域不可或缺的基礎(chǔ)架構(gòu),并催生了完善的數(shù)據(jù)處理與存儲(chǔ)支持服務(wù)生態(tài)。
一、海量數(shù)據(jù)處理的核心挑戰(zhàn)與離線批處理
海量數(shù)據(jù)處理并非單純地“放大”傳統(tǒng)流程,它面臨著三大核心挑戰(zhàn):數(shù)據(jù)規(guī)模巨大、計(jì)算復(fù)雜度高、硬件故障成為常態(tài)。離線批處理技術(shù)正是為應(yīng)對(duì)這些挑戰(zhàn)而設(shè)計(jì)。其核心理念是“分而治之”:將龐大的數(shù)據(jù)集分割成多個(gè)小塊(分片),分發(fā)到大規(guī)模廉價(jià)服務(wù)器集群中進(jìn)行并行計(jì)算,最后匯果。這種模式不要求實(shí)時(shí)響應(yīng),允許在數(shù)分鐘到數(shù)小時(shí)甚至更長(zhǎng)時(shí)間內(nèi)完成計(jì)算任務(wù),非常適合用于日志分析、數(shù)據(jù)倉(cāng)庫(kù)ETL、歷史數(shù)據(jù)挖掘、報(bào)表生成等場(chǎng)景。
二、Hadoop:離線批處理的技術(shù)基石
Hadoop是一個(gè)開源的分布式系統(tǒng)基礎(chǔ)架構(gòu),它完美地實(shí)現(xiàn)了離線批處理的理念,主要由兩大核心組件構(gòu)成:
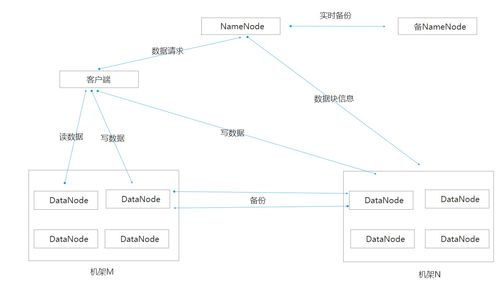
- HDFS(Hadoop Distributed File System):分布式文件系統(tǒng)。它是海量數(shù)據(jù)存儲(chǔ)的基石。HDFS將文件分割成固定大小的數(shù)據(jù)塊(默認(rèn)為128MB),并以多副本(默認(rèn)為3份)的形式分散存儲(chǔ)在集群的各個(gè)節(jié)點(diǎn)上。這種設(shè)計(jì)提供了極高的容錯(cuò)性(個(gè)別節(jié)點(diǎn)宕機(jī)不影響數(shù)據(jù)可用性)和吞吐量(支持?jǐn)?shù)據(jù)并行讀寫),滿足了海量數(shù)據(jù)存儲(chǔ)的需求。
- MapReduce:分布式計(jì)算框架。它是海量數(shù)據(jù)計(jì)算的引擎。其計(jì)算模型分為兩個(gè)階段:
- Map(映射)階段:將輸入數(shù)據(jù)分片,由多個(gè)Map任務(wù)并行處理,輸出一系列中間鍵值對(duì)。
- Reduce(歸約)階段:將Map階段輸出的、擁有相同鍵的中間結(jié)果進(jìn)行匯總、計(jì)算,生成最終結(jié)果。
這種簡(jiǎn)單的模型屏蔽了底層復(fù)雜的分布式編程細(xì)節(jié)(如任務(wù)調(diào)度、節(jié)點(diǎn)通信、容錯(cuò)處理),使開發(fā)者能夠?qū)W⒂跇I(yè)務(wù)邏輯本身。
三、圍繞Hadoop的數(shù)據(jù)處理與存儲(chǔ)支持服務(wù)
單純的Hadoop核心組件如同汽車的引擎和底盤,要使其高效、穩(wěn)定、易用地運(yùn)行,還需要一整套支持服務(wù)。這些服務(wù)構(gòu)成了現(xiàn)代大數(shù)據(jù)平臺(tái)的關(guān)鍵部分:
1. 資源管理與調(diào)度服務(wù)
- YARN(Yet Another Resource Negotiator):Hadoop 2.0引入的核心組件,它將資源管理與作業(yè)調(diào)度/監(jiān)控功能分離。YARN作為一個(gè)集群資源管理器,負(fù)責(zé)統(tǒng)一管理集群的計(jì)算資源(CPU、內(nèi)存),并為上層各種計(jì)算框架(如MapReduce、Spark、Flink)提供資源調(diào)度服務(wù),使Hadoop從單一的批處理系統(tǒng)演進(jìn)為一個(gè)多任務(wù)、多租戶的數(shù)據(jù)操作系統(tǒng)。
2. 數(shù)據(jù)集成與處理服務(wù)
- Apache Hive:基于Hadoop的數(shù)據(jù)倉(cāng)庫(kù)工具,它提供了類似SQL的查詢語(yǔ)言(HQL),可以將結(jié)構(gòu)化的數(shù)據(jù)文件映射為一張數(shù)據(jù)庫(kù)表,并將SQL語(yǔ)句自動(dòng)轉(zhuǎn)換為MapReduce或Tez/Spark任務(wù)執(zhí)行,極大降低了數(shù)據(jù)開發(fā)人員的學(xué)習(xí)和使用門檻。
- Apache Pig:提供了一種高級(jí)腳本語(yǔ)言(Pig Latin),用于描述數(shù)據(jù)流處理過程,同樣會(huì)編譯成MapReduce任務(wù)執(zhí)行,適合進(jìn)行復(fù)雜的數(shù)據(jù)流水線操作。
- Apache Sqoop:用于在Hadoop與結(jié)構(gòu)化數(shù)據(jù)庫(kù)(如MySQL, Oracle)之間高效傳輸批量數(shù)據(jù)的工具。
- Apache Flume:一個(gè)高可用的、高可靠的分布式日志采集、聚合和傳輸系統(tǒng),常用于將海量日志數(shù)據(jù)從各個(gè)服務(wù)器實(shí)時(shí)攝入HDFS。
3. 數(shù)據(jù)存儲(chǔ)優(yōu)化與管理服務(wù)
- Apache HBase:構(gòu)建在HDFS之上的分布式、面向列的NoSQL數(shù)據(jù)庫(kù)。它彌補(bǔ)了HDFS隨機(jī)讀寫能力弱的缺點(diǎn),支持對(duì)海量數(shù)據(jù)的低延遲、隨機(jī)訪問,適用于實(shí)時(shí)查詢場(chǎng)景。
- Apache Parquet / ORC:高效的列式存儲(chǔ)格式。與傳統(tǒng)的行式存儲(chǔ)相比,它們?cè)谔幚碇恍枰樵儾糠至械姆治鲂腿蝿?wù)時(shí),能極大減少I/O,提升查詢性能,并支持更好的壓縮。
- Apache ZooKeeper:分布式協(xié)調(diào)服務(wù),為Hadoop生態(tài)中的許多組件(如HBase, Kafka, YARN)提供可靠的分布式鎖、配置維護(hù)、命名服務(wù)等,是保障集群穩(wěn)定運(yùn)行的“潤(rùn)滑劑”。
四、與展望
以Hadoop為代表的離線批處理技術(shù),通過分布式存儲(chǔ)和計(jì)算,從根本上解決了海量數(shù)據(jù)處理的可行性問題。而圍繞其構(gòu)建的豐富的數(shù)據(jù)處理與存儲(chǔ)支持服務(wù)生態(tài),則從易用性、效率、功能完備性等方面將這種能力產(chǎn)品化、服務(wù)化,使之成為企業(yè)數(shù)據(jù)中臺(tái)的堅(jiān)實(shí)底座。盡管如今實(shí)時(shí)流處理(如Spark Streaming, Flink)和交互式查詢(如Impala, Presto)技術(shù)發(fā)展迅速,但在處理超大規(guī)模歷史數(shù)據(jù)、運(yùn)行復(fù)雜ETL作業(yè)和生成深度分析報(bào)表方面,Hadoop離線批處理技術(shù)因其成熟度、穩(wěn)定性和成本優(yōu)勢(shì),依然占據(jù)著不可替代的核心地位。隨著云原生、存算分離等理念的深入,Hadoop生態(tài)也在不斷進(jìn)化,持續(xù)為海量數(shù)據(jù)的價(jià)值挖掘提供強(qiáng)大動(dòng)力。